
Recent Posts
zimslog
[R] Baseline Demographic Characteristics (기술통계량) 본문
1. 기술통계량 확인
#요약통계량 확인
summary(data)
#summary보다 많이 보여줌
library(psych)
describe(data[, c("Age", "difftime")])
#좀 더 많이 보여줌
library(pastecs)
round(stat.desc(data[, c("Age", "difftime")], basic = T, desc = T, norm = T, p= 0.9))
2. 기술통계량 테이블 (finalfit, knitr)
# finalfit :: summary_factorlist
explanatory = c("age.factor", "sex.factor", "obstruct.factor") #설명변수
dependent = 'mort_5yr' #독립변수(그룹)
colon_s %>%
summary_factorlist(dependent, explanatory,
p=TRUE, add_dependent_label=TRUE) -> t1
#knitr :: kable()
kable(t1, #테이블화할 데이터
caption = "knitr 패키지의 kable() 함수를 이용한 표 그리기", #제목
align=c("c","l","l","l","r")) #정렬
3. 커스텀 기술통계량 테이블
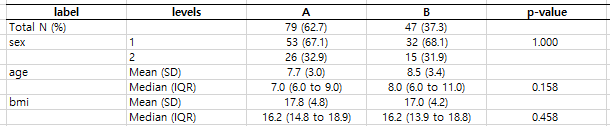
내가 쓰려고 만든 코드이고,
위 테이블 형태로 범주형 변수의 경우 교차표를, 연속형 변수의 경우 Mean(SD), Median(IQR)값을 모두 나타내준다.
- mean_p가 T인 경우 연속형 변수의 모수적 방법(t-test or ANOVA)에 대한 p-value를 계산해준다.
- median_p T인 경우 연속형 변수의 비모수적 방법(mann-whitney U test or Kruskal-Wallis test)에 대한 p-value를 계산해준다.
- cat_parm은 T일 경우 범주형 변수에 대해 chisq-test, F일 경우 fisher's exact test에 대한 p-value를 표현한다.
baseline_table <- function(df, dependent, mean_p = F, median_p = T, cat_parm = F){
col_list <- colnames(df)
explanatory = col_list[col_list != dependent]
dependent = dependent
mean <- df %>%
summary_factorlist(dependent, explanatory, cont = 'mean',
p=mean_p, add_col_totals = TRUE)
median <- df %>%
summary_factorlist(dependent, explanatory, cont = 'median', p_cat = 'fisher',
p=median_p, add_col_totals = TRUE)
mean <- data.frame(mean) %>% mutate(index=row_number())
median <- data.frame(median) %>% mutate(index=row_number())
# Continuous
mean.values <- mean[mean$levels == 'Mean (SD)',]
median.values <- median[median$levels == 'Median (IQR)',]
mm <- arrange(bind_rows(mean.values, median.values), label)
mm <- mm %>%
mutate(label = ifelse(row_number() %% 2 == 0, '', label),
test = if (n_distinct(df[[dependent]]) > 2) {
# 그룹이 세 개 이상인 경우
ifelse(row_number() %% 2 == 0,'Kruskal-Wallis test','ANOVA') # ANOVA, Kruskal-Wallis
} else {
# 그룹이 두 개 이하일 경우
ifelse(row_number() %% 2 == 0,'mann-whitney U test','t-test') # t-test, mann-whitney U test
}
)
# Categorical
if(cat_parm){
# chisq.test
cat.values <- mean[mean$levels != 'Mean (SD)',]
cat.values$test <- 'chi-square test'
}else{
# fisher.test
cat.values <- median[median$levels != 'Median (IQR)',]
cat.values$test <- "fisher's exact test"
}
# Result
result <- bind_rows(cat.values, mm) %>%
arrange(index) %>%
mutate(p = ifelse(is.na(p), '', p),
test = ifelse(p == '', '', test)) %>%
select(-index)
return(result)
}
'Data Analysis > R' 카테고리의 다른 글
| [R] Logistic Regression Probability Curve (0) | 2023.12.24 |
|---|---|
| [R] Diagnostic Test (진단 테스트) (2) 진단 도구 간 성능 비교 (0) | 2023.12.12 |
| [R] Diagnostic Test (진단 테스트) : Sensitivity, Specificity, Accuracy (민감도, 특이도, 정확도) (0) | 2023.12.08 |
| [R] 자주 쓰는 단축키 (0) | 2023.11.24 |
| [R] apply function (apply, sapply, lapply, mapply, vapply) (0) | 2023.11.23 |