
zimslog
[ML/DL] Ensemble (앙상블 기법) 본문
Ensemble (앙상블 기법)
이번 포스팅에서는 분류 예측 문제를 다룰 때 자주 사용되는 앙상블 기법에 대해 알아보고자 한다.
앙상블 기법이 무엇인지 개념을 알아보고, 어떤 종류가 있는지 알아보도록 하겠다.
1. 앙상블 기법이란?
여러 개의 분류 모델을 결합해서 최적의 모델을 만드는 방법을 앙상블 기법이라고 한다.

여러 모델을 결합한 앙상블 모델은 단일 모델보다 더 뛰어난 성능을 보이고, 보다 일반화(generalized)된 모델이기 때문에 과적합(overfitting) 문제를 감소시킨다는 장점이 있다.
이론적으로는 M개의 독립적인 단일 모델을 결합한 앙상블 모델의 오류가 M개 모델 평균 오류의 1/M 수준으로 감소하는데, 현실적으로는 독립성 가정이 지켜지지 않는 경우가 많기 때문에, 앙상블 모델의 오류가 단일 모델의 평균 오류보다는 최소한 같거나 낮은 오류를 나타내게 된다.
즉, 앙상블 모델이 1등 모델보다 성능이 우수하다고 할 수는 없지만, 적어도 단일 모델들의 평균 오류보다는 항상 우수한 성능을 보인다.
앙상블 모델에 사용되는 단일 모델들이 다양할수록 앙상블의 효과를 높이는데 이상적이다. 따라서, 앙상블을 구성할 때 중요하게 고려해야할 점이 "모델의 다양성을 어떻게 확보할 것인가?" 와 "모델들을 어떻게 결합할 것인가?" 이다.
2. 앙상블 기법 종류
모델들을 결합하는 방법인 앙상블 기법 종류를 알아보기 전에, 편향(bias)와 분산(Variance)에 대한 개념을 먼저 알아야 한다. 관련 내용은 이전 포스팅을 참고!
2024.05.21 - [Data Science] - [ML/DL] 편향(Bias)과 분산(Variance)
2.1 Bagging : Bootstrap Aggregating
Bagging은 복원 추출 방법을 통해 샘플 데이터를 여러 번 뽑아서 각각의 모델의 학습시킨 다음, 결과를 집계(Aggregation)하는 방법이다. 이 때 추출된 개별 데이터셋을 Bootstrap이라고 하고, Bootstrap의 크기는 원래 데이터의 크기와 동일하다.
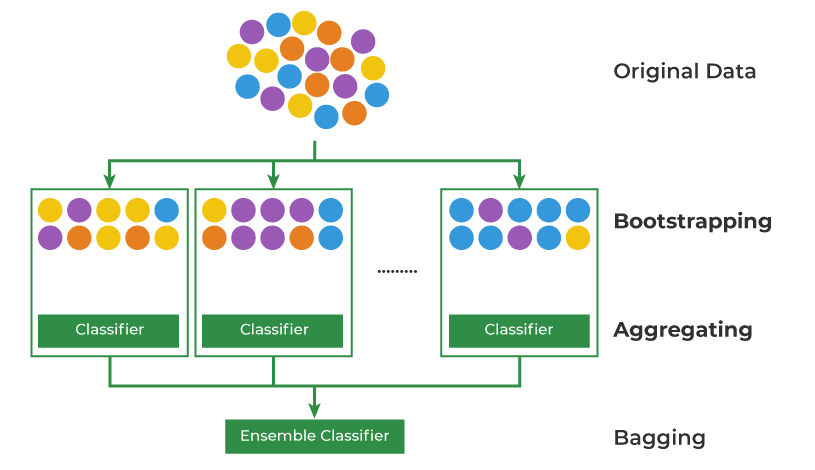
Bagging 방법은 개별 모델의 분산이 높고 편향은 낮은 경우에 일어날 수 있는 과적합(overfitting)을 피하기 위해 사용하기 적절하다. (여러 모델의 결과를 결합하여 일반화 시키기 때문)
일반적으로 Categorical Data는 투표(Voting) 방식으로 집계하고, Continuous Data는 평균(Average)으로 집계한다.
대표적인 Bagging 알고리즘으로는 Random Forest 모델이 있다.
단일 Decision Tree 모델이 가지는 과적합 문제를 보완하는 분류 문제에서 가장 많이 사용되는 모델이다.
2024.01.10 - [Data Science/Classification] - [머신러닝] Decision Tree (의사결정나무)
2.2 Boosting
Bagging에서는 각 모델이 독립적으로 학습을 수행하였는데, Boosting은 이전 모델의 학습이 다음 모델의 학습에 영향을 미친다. 이전 모델의 학습 결과에 따라 오분류된 개체는 높은 가중치를, 정분류된 개체는 낮은 가중치를 부여하고, 다음 모델이 잘못 분류된 데이터에 집중해서 학습을 수행하도록 하는 과정을 반복하게 된다.
Boosting 기법은 높은 정확도를 보이지만 과적합의 위험이 Bagging보다 크고 직렬 학습으로 인해 속도가 느리다는 단점이 있다.

Bagging 알고리즘으로는 AdaBoost, Gradient Boosting, XGBoost, LightGBM 등이 있다.
2.3 Voting
Voting은 여러 개의 분류기의 투표를 통해 최종 결과를 예측한다는 점에서 Bagging과 유사하다.
다른 점은 Bagging은 같은 단일 모델들이 서로 다른 샘플링 데이터로 학습하지만,
Voting은 서로 다른 단일 모델들이 같은 데이터셋을 기반으로 학습한다는 점이다.
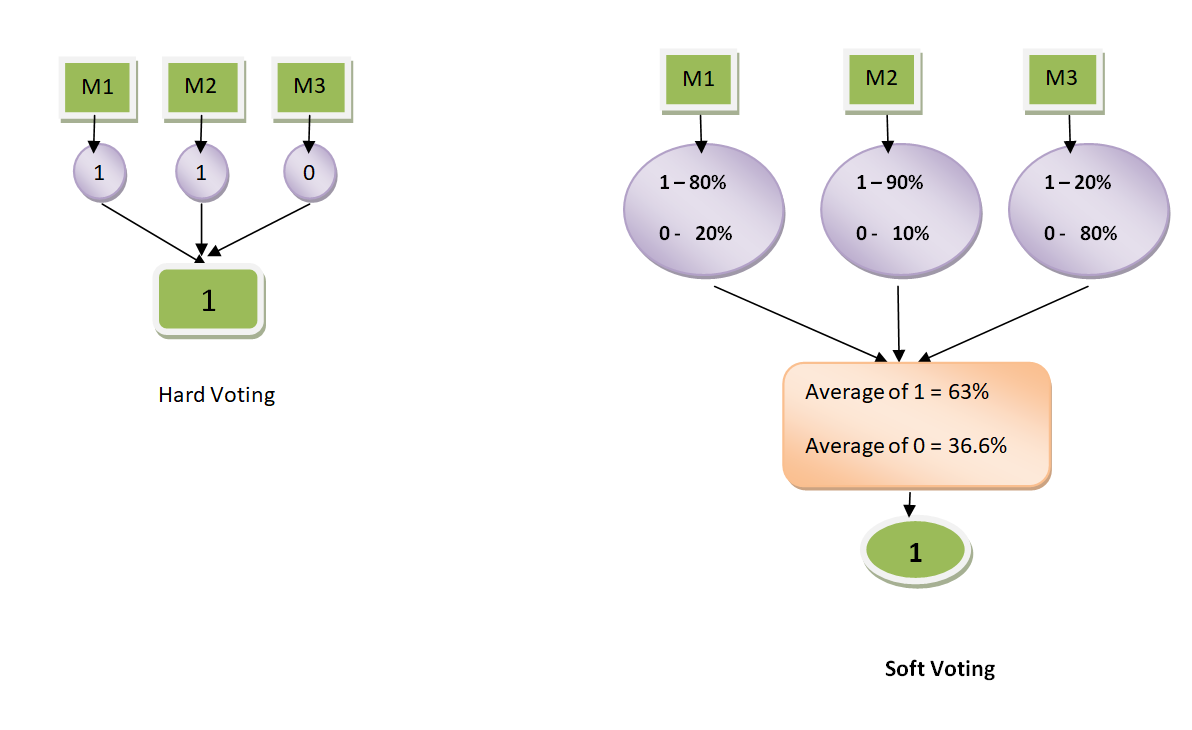
Voting에는 Hard Voting과 Soft Voting 두 가지 방법이 있다.
Hard Voting은 다수결 원칙처럼 예측 결과 값 중 다수의 분류기가 선택한 예측값을 최종 결과값으로 선정하는 방법이고,
Soft Voting은 분류기들의 각 결정 확률을 평균내서 확률이 가장 높은 최종 레이블을 최종 결과 값으로 선정하는 방법이다.
2.4 Stacking (with Cross Validation)
Stacking 방법은 위의 방법들과 접근법이 조금 다르다.
Stacking은 단일 모델이 예측한 데이터를 meta data로 하여 다시 학습한다는 컨셉이다.
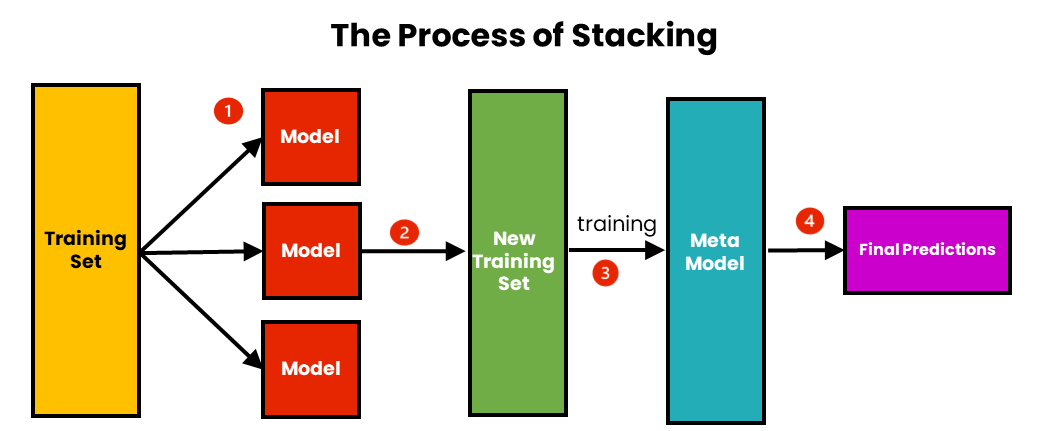
기존 데이터로 학습하는 단일 모델들을 Base Learner라고 하고, meta data로 학습하는 최종 모델을 Meta Learner라고 한다. Base Learner들은 과적합 문제를 방지하기 위해 Cross Validation 방법으로 데이터를 쪼개서 학습을 진행하고,
Meta Learner는 Base Learner의 validation set과 test set을 모아서 만든 meta train set, meta test set으로 학습을 진행한다.
Stacking 방법은 메타 학습을 통해 더 완성도 있는 모델을 만들 수 있지만, 아무래도 계산량이 많다는 단점이 존재한다.
* Reference
- https://medium.com/dawn-cau/머신러닝-앙상블-학습-이란-cf1fcb97f9d0