
Recent Posts
zimslog
[R] K-Means Clustering 본문
이번 포스팅에서는 R에서 K-Means Clustering을 수행하는 방법에 대해 알아보겠다.
K-Means Clustering에 대한 개념 설명은 아래 게시글을 참고하면 된다.
2024.02.26 - [Machine Learning/Clustering] - [머신러닝] K-Means Clustering
[머신러닝] K-Means Clustering
K-Means Clustering 1) K-Means 알고리즘이란? 비지도학습에 속하는 머신러닝 기법으로 데이터를 유사한 특성을 가진 K개의 군집(Cluster)으로 묶는 알고리즘이다. K개의 점과의 거리를 기반으로 구현된다
meowstudylog.tistory.com
K-Means Clustering은 아래 절차대로 수행하면 된다.
- 데이터 분할 및 전처리
- 군집 수 결정
- 군집화 및 군집 확인
- 새로운 데이터에 군집 할당
1. 데이터 분할 및 전처리
caret 패키지를 활용해서 데이터를 Train set / Test set으로 split 해준다.
library(caret)
set.seed(123)
inTrain <- createDataPartition(y = KData$cluster, p = 0.7, list = F)
training <- iris[inTrain,]
testing <- iris[-inTrain,]
training
데이터 변수들의 스케일이 다른 경우, 표준화 작업을 통해 단위를 맞춰준다.
K-Means Clustering은 관측치간 거리를 활용하기 때문에 변수들의 scale이 결과에 큰 영향을 미칠 수 있다.
training.data <- scale(training[-5])
summary(training.data)
2. 군집 수 결정
# 1. Choose K (Elbow approach)
tot.withinss <- vector('numeric', length = 10)
for(i in 1:10){
kDet <- kmeans(training.data[,-5], i)
tot.withinss[i] <- kDet$tot.withinss
}
as.data.frame(tot.withinss) %>%
ggplot(aes(x=seq(1,10), y=tot.withinss)) +
geom_point(col = "#F8766D") +
geom_line(col = "#F8766D") +
theme(axis.title.x.bottom = element_blank())
=> K가 완만해지는 지점인 5로 군집 수 결정
3. 군집화 및 군집 확인
# 2. cluster data
customerClusters <- kmeans(training.data[,-5], 5)
customerClusters
# 3. Visualise clusters
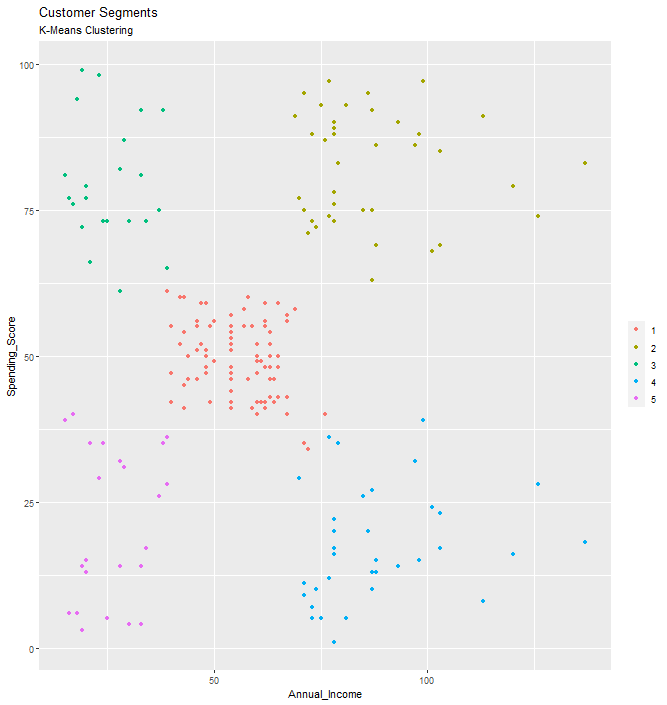
training.data %>%
ggplot(aes(x=Annual_Income, y = Spending_Score)) +
geom_point(stat = 'identity', aes(color=as.factor(customerClusters$cluster))) +
scale_color_discrete(name='') +
ggtitle('Customer Segments', subtitle = 'K-Means Clustering')
4. 새로운 데이터에 군집 할당
training.data <- as.data.frame(training.data)
modFit <- train(x = training.data[,-5],
y = training$cluster,
method = "rpart")
testing.data <- as.data.frame(scale(testing[-5]))
testClusterPred <- predict(modFit, testing.data)
table(testClusterPred ,testing$Species)
* 캐글 예제 참고
https://www.kaggle.com/code/ioannismesionis/mall-customer-segmentation-unsupervised-learning
'Data Science > R' 카테고리의 다른 글
| [R] Caret Package로 모델 학습 및 튜닝하기 (0) | 2024.05.29 |
|---|---|
| [R] Decision Tree (의사결정나무) (0) | 2024.01.15 |
'Data Science/R' Related Articles
more
